

A big part of machine learning is data cleanup and feature engineering. A good tool in your data science toolkit will be label encoding. Text fields can be valuable for natural language processing, but not when you want to run something numeric against them. For example, what if your answers in the data are “yes”, “no” and “maybe”? You may only care about a yes or no? Ideally, you’d want to change these to a 1 or 0.
Often categorical variables need to be converted into integers so our models can use the data. For this, we can use sklearn’s LabelEncoder. This assigns an integer to each value of the categorical feature and replaces those values with the integers.
The documentation for sklearn is here, but frankly if you are new to machine learning it’s not very helpful as a way to learn.
We are going to convert category, currency and country in the following data example:
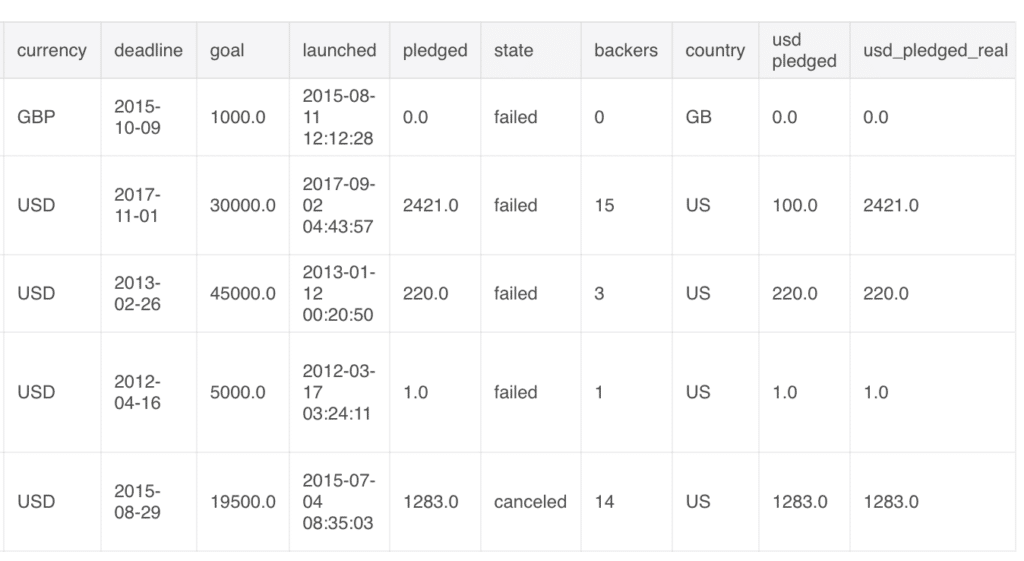
For the categorical variables category, currency, and country let’s convert them into integers so our model can use the data. For this, I’ll use sklearn’s LabelEncoder. This assigns an integer to each value of the categorical feature and replaces those values with the integers.
[code lang=”python”] from sklearn.preprocessing import LabelEncodercat_features = [‘category’, ‘currency’, ‘country’] encoder = LabelEncoder()
# Apply the label encoder to each column
encoded = ks[cat_features].apply(encoder.fit_transform)
encoded.head(10)
[/code]
And your head will be below:
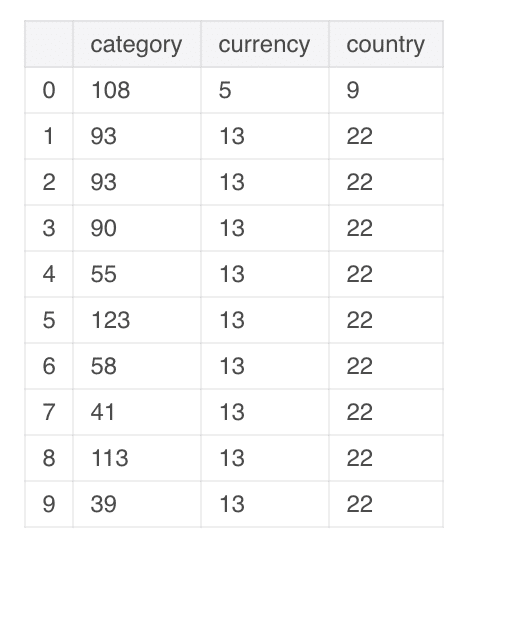
What you will notice is an integer for each item. Clearly there are many categories since the numbers range from 39 to 123. The goal is to be able to look at categories that we can predict to be successful. Similarly with country or currency–might even find interesting wins if the country is Germany but use the American Dollar or a Euro. This also allows us to easily visualize the data!



